
In today’s fast-moving world of AI and data science, developing machine learning models is only part of the challenge. More often than not, the most difficult phase is deploying the machine learning model quickly, safely, and at scale. Luckily, Amazon Web Services (AWS) has a lot of possessions to effectively deploy machine learning models, and AWS SageMaker is an accomplished service that helps developers and data scientists create, train, and deploy ML models.
In this article, I present a step-by-step process to deploy machine learning models using AWS SageMaker. My intention is to create a useful guide for other data science enthusiasts, professionals, or students looking to build their practical experience. This article is a useful introduction to one of the key stages in the life-cycle of an ML project.
What is AWS SageMaker?
Amazon SageMaker has the capability to function as a cloud platform fully managed by AWS. The greatest use of the platform is for building, training, and deploying methods for ML models at scale. It was released in 2017, which decreases most of the heavy lifting that usually goes into ML development, and hence, users can focus on the science and not on infrastructure.
End-to-End Machine Learning Platform
Being an end-to-end platform, it has tools for every stage in an ML process. From data pre-processing and Labeling-Gathering and Wrangling-Model building, training, tuning, and deployment-the entire workflow is wrapped in a single, integrated solution. The service accommodates popular frameworks such as TensorFlow, PyTorch, MXNet, and scikit-learn, and it provides built-in algorithms one can use right away for classification, regression, and clustering.\
Integrated Development and Training Environment
AWS offers SageMaker Studio as an integrated development environment (IDE) where users can write code, visualize data, and monitor training jobs in one place. The platform provides cloud-hosted, scalable Jupyter notebooks with no server management required. SageMaker also supports distributed training and hyper parameter tuning, thereby whichever simple experiments or large production workloads you might encounter are all addressable.
Flexible Deployment Options
SageMaker takes away the heavy lifting of deploying trained models. Once a model has been trained and validated, teams can seamlessly deploy it through SageMaker on an auto-scaled managed hosting environment based on traffic. It supports A/B testing and multi-model endpoints so teams can efficiently manage multiple versions of a model. With SageMaker Neo, a model is served on edge devices by compiling it for highest efficiency on multiple hardware platforms.
Key Features:
- Jupyter notebooks for easy experimentation.
- Built-in algorithms and frameworks (TensorFlow, PyTorch, Scikit-learn, XGBoost).
- Managed training and tuning environments.
- Scalable inference endpoints for real-time predictions.
- Model monitoring and automatic scaling.
Why Use AWS SageMaker for Deployment?
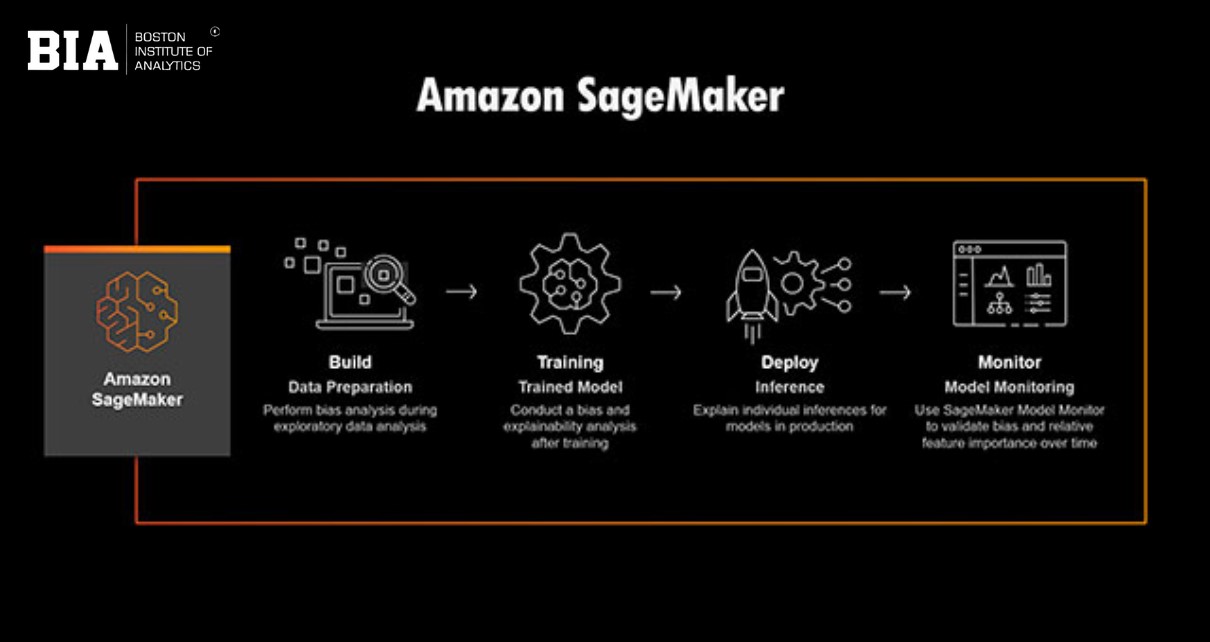
Owing to its simpler interface and greater potential, Amazon SageMaker serves as a popular deployment platform among businesses that transfer models from development to production systems efficiently. The platform helps eliminate the complexity usually attached to deployments so that data scientists and developers can focus on innovations.
Seamless Model Hosting
SageMaker offers its users a fully managed hosting environment for deploying trained machine learning models, so there is no need to think about provisioning servers, networking configurations, or scaling policies. The platform takes care of the infrastructure and allows deployment of models with a few lines of code. SageMaker automatically provisions the compute resources necessary and maintains a high level of availability, thus being suitable for production workloads.


Scalability and Performance
Scaling automatically depending on traffic was amongst the most important advantages of deployment with SageMaker. This ensures responsiveness during times of heavy load without much, if any, manual intervention. SageMaker allows for multi-model endpoints, where several models can be hosted on a single endpoint. This reduces costs and streamlines the deployment architecture for applications that require several models.
Monitoring and Optimization
SageMaker offers a facility for monitoring deployed models. With SageMaker Model Monitor, users can detect data drift, abnormalities, and changes in model behaviour over time. This capability ensures proactive maintenance, giving assurance that the model stays up to date and accurate. Integration with Amazon CloudWatch provides real-time insights into performance metrics, which helps operations to optimize, and identify potential issues before they materialize.
Security and Integration
Security underscores the deployment capabilities of SageMaker. SageMaker integrates with AWS Identity and Access Management (IAM) for fine-grained access control to deployed models. Or, SageMaker can leverage additional AWS services, making it easy to develop end-to-end machine learning workflows and connect models to applications with secure APIs.
Step-by-Step Guide to Deploying Machine Learning Models on AWS SageMaker
Deploying machine-learning models on AWS SageMaker is a different stage-oriented process that includes activities transforming a model from developmental to a production environment, i.e., one that is fully functional and scalable. Using any model approach-SageMaker offers tools and automation for the entire process. For a detailed description of deploying a machine-learning model using SageMaker, see below.
Preparing the Environment
At the stage of deployment, it is vital to set up the AWS environment. This entails creating an AWS account and configuring necessary permissions through IAM roles. These roles specify which AWS services SageMaker can use on your behalf to access, e.g., get data from S3, or write logs to CloudWatch. Another step would be setting up a SageMaker notebook instance or SageMaker Studio to start interacting with the platform.
Uploading Data and Training the Model
If you start with data sets from scratch, your next step involves uploading them to Amazon S3. S3 is SageMaker’s primary data storage for both training and inference. With the data in place, either a built-in algorithm of SageMaker can be applied, your own custom algorithm, or a popular framework such as TensorFlow or PyTorch may be used. Training jobs may be created via the SageMaker Python SDK or from the AWS Management Console. You specify your training parameters, training script, and launch the training job onto scalable compute instances.
Saving and Registering the Model
Post training, SageMaker exports the model artifacts to an S3 bucket. These artifacts represent the trained model and all associated files needed for inference. To prepare the model to be served, you may opt to register it with the SageMaker Model Registry. This lets you manage model versions, assign relevant metadata, and keep track of deployment history, which brings value in maintaining and auditing your models over time.
Creating the Inference Endpoint
In a nutshell, an inference endpoint has to be created to deploy the model. SageMaker models are defined, using the model artifacts and the inferencing code. Once done, they create an endpoint configuration specifying the compute instance type and scaling options. Furthermore, they deploy the model by creating the endpoint, which acts as an HTTPS live API that applications call to get online prediction.
Testing and Monitoring the Deployment
After that, test the live endpoint to ensure that the returned predictions are accurate and timely. Some test requests may be sent using the SageMaker SDK, or REST clients may be used. Integration with CloudWatch and Model Monitor is also available in SageMaker to help with live monitoring of prediction latency, throughput, and accuracy, and it also helps with detecting performance issues, drifts in the model, or anomalies in input data.
Scaling and Updating the Model
SageMaker endpoints can be adjusted manually or automatically, based on your traffic requirements. You can also update your model, without taking the endpoint down, since model versioning allows you to deploy new models to the same endpoint. For more advanced use cases, there are capabilities that allow multiple models to be managed effectively, such as multi-model endpoints and A/B testing.
Best Practices for Deploying Machine Learning Models on AWS

When deploying machine learning models through AWS, there is a requirement for wise planning to remain reliable, scalable, and maintainable. Using Amazon SageMaker’s Model Registry to manage model versions is one of the main best practices. It immediately creates tracking and governance, thus providing options to safely roll back or update models.
Security should never be compromised, hence never allow access to models, endpoints, or data without using AWS Identity and Access Management (IAM). Always encrypt data, whether in transit or at rest, through Amazon KMS (Key Management Service). For real-time applications, auto-scaling endpoints are an awesome way to manage variable loads right from implementation, without required participation from an end-user.
Monitoring helps maintain model performance when in production. Use SageMaker Model Monitor to detect drift in model input data and anomalies in prediction quality. Set this up together with Amazon CloudWatch for real-time alerts and logs that will fast track diagnosis.
Containerizing models using SageMaker Inference Containers or BYO (Bring Your Own) Docker ampules ensures steadiness across surroundings. Additionally, use A/B testing and shadow dispositions to validate new models before fully replacing older ones.
Finally, systematize arrangements with CI/CD pipelines using AWS Code Pipeline or SageMaker Pipelines. This reduces manual errors and accelerates the model deployment lifecycle. Following these best practices helps ensure your ML arrangements on AWS are secure, scalable, and robust.
Real-World Applications of ML Model Deployment

Machine learning models are already being used in healthcare settings as a diagnostic aid and treatment plan support. For example, some machine learning models trained on medical imaging data are deployed and working in real-time to detect disease including cancer, pneumonia or diabetic retinopathy. Deployed machine learning models will analyze a scan and produce feedback in seconds to a physician, improving accuracy and speeding up the time of diagnosis.
Financial Fraud Detection
In the finance industry, machine learning models are deployed to investigate suspicious transactions, or fraud. These models monitor transaction data for suspicious spending patterns and user behaviour. In deployed and real-time systems, these machine learning models can flag a transaction as suspicious, and trigger a response or heightened security instantly to mitigate the risk of fraud.
Retail Personalization
E-commerce platforms, like Shopify or eBay, are using deployed recommendation models to tailor shopping experiences for customers online. Instead of serving users with the same experience, they utilize the users’ historical data, behaviours, and preferences to provide personalized, and chatty models to recommend products and experiences. Deployed recommendation machine learning models increase engagement and encourage customers to purchase products.
Manufacturing and Predictive Maintenance
Businesses in manufacturing, deployed ML models should perform predictive maintenance using sensor data from machines to predict a machine failure before it occurs. This reduces downtime, optimizes maintenance schedules and extends machinery useful life.
Autonomous Vehicles
Deployed ML models in self-driving cars process visual and sensory data in real-time during operation to decide the direction of travel, whether to avoid obstacles in the environment, and to comply with traffic laws. There are significant expectations of accuracy and low latency once deployed, and model deployment in self-driving cars relies on already established model deployment procedures that meet both in-vehicle robot deployment needs.
Final Thoughts
Implementing machine learning models is a key tactic in leveraging raw data into actionable intelligence. While the modelling phase gets significant attention, it’s only when models are operationalized and put into production that they create any kind of real value to a business.
AWS SageMaker can simplify that journey by providing a powerful, scalable, and secure environment for the complete ML life cycle; from pre-processing, to training, deployment, and monitoring. To someone wanting to learn more about deploying machine learning considerations into cloud environments, or an experienced data scientist looking to implement optimisation of an ML pipeline, knowledge in SageMaker will enable you to maximise your abilities.
